Predicting Attrition in Healthcare Industry
Predicting Attrition in Healthcare Industry
In this exercise, classification models will be used to answer what factors lead to employee attrition in the Healthcare industry. The dataset used is a Kaggle dataset which can be found here.
We will go through data cleaning, investigating distributions, exploratory data analysis, and then finally modeling using several classification models.
The link to the jupyter notebook is located here.
Exploratory Data Analysis
The dataset consists of numeric features such as Age, hourly, daily, and monthly rate, as well as monthly income. Also has features that deal with years at current company, years worked, years in current role etc… The categorical features consist of department, education, job level, job involvement, gender, marital status.
The data consists of no missing values, so there is no need to impute missing values or remove the observations. As far as numeric columns, there are outliers, and will use Standard Scalar before modeling.
The data consist of 1,676 rows and 35 columns, and the dependent variable, Attrition, consists of 12% attrition, 88% no attrition.
Below shows the correlation among the numeric features. The heatmap shows that the following features are positively correlated with each other: Age, MonthlyIncome,TotalWorkingYears, YearsatCompany,YearsInCurrentRole, YearsSinceLastPromotion,YearswithCurrManager.
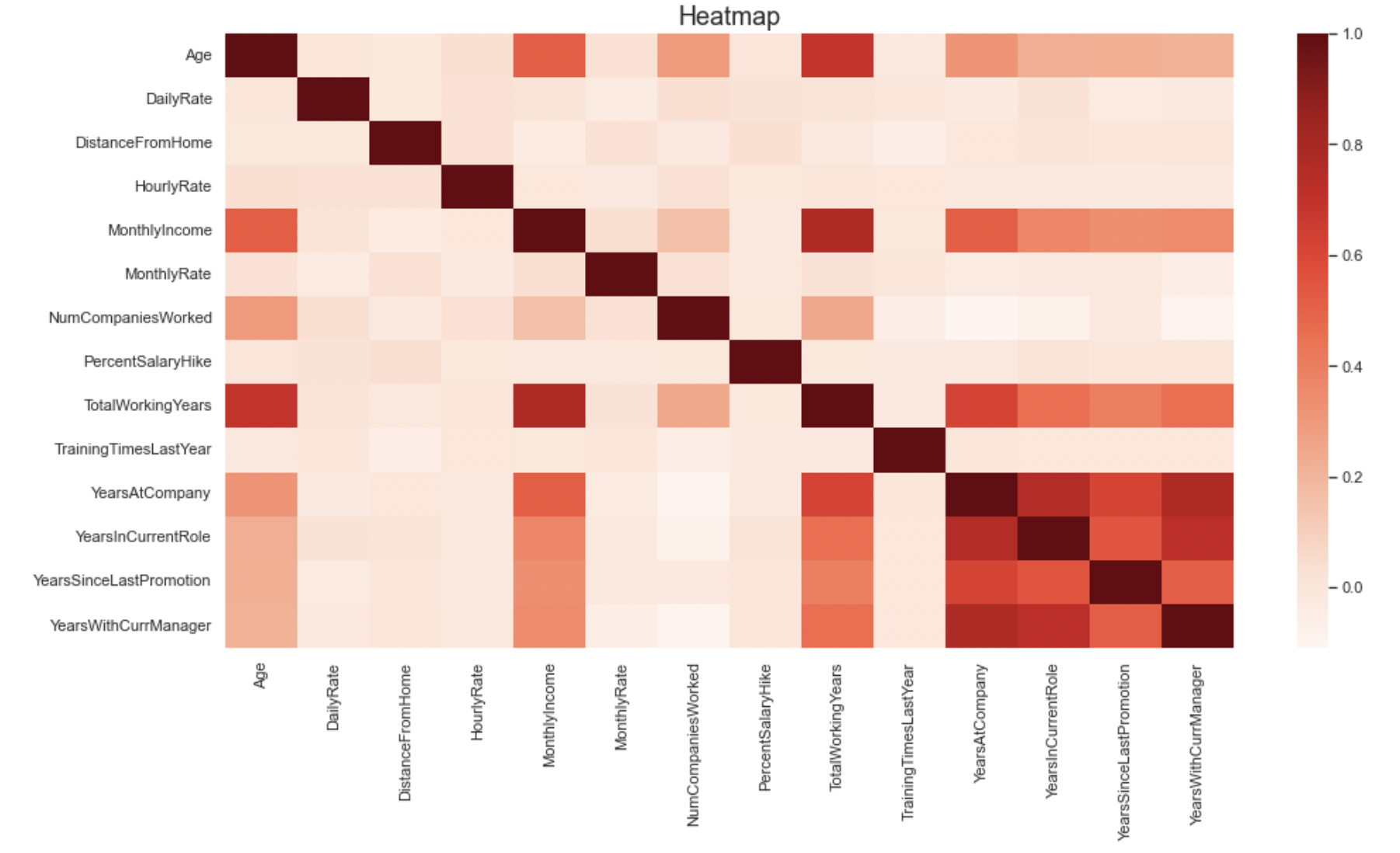
There were other plots made that looked at the interactions of various features, for those, please take a look at the jupyter notebook (link above).
Modeling
The data was transformed using Standard Scaler and One Hot Encoder. The models used in this analysis were:
- Logistic Regression
- With and Without Recursive Feature Elimination (RFE)
- Random Forest
- Extra Trees
- Gradient Boosting
GridsearchCV was used for hyperparameter tuning. The main goal should be to reduce False Negatives, and by that i mean we want to reduce the scenario where the model predicted “No Attrition” and the data showed “Attrition”. The reason why I feel this should be main goal, is that as an employer, I would want to know before an employee leaves as I do not want to be short handed and have enough time to find replacement.
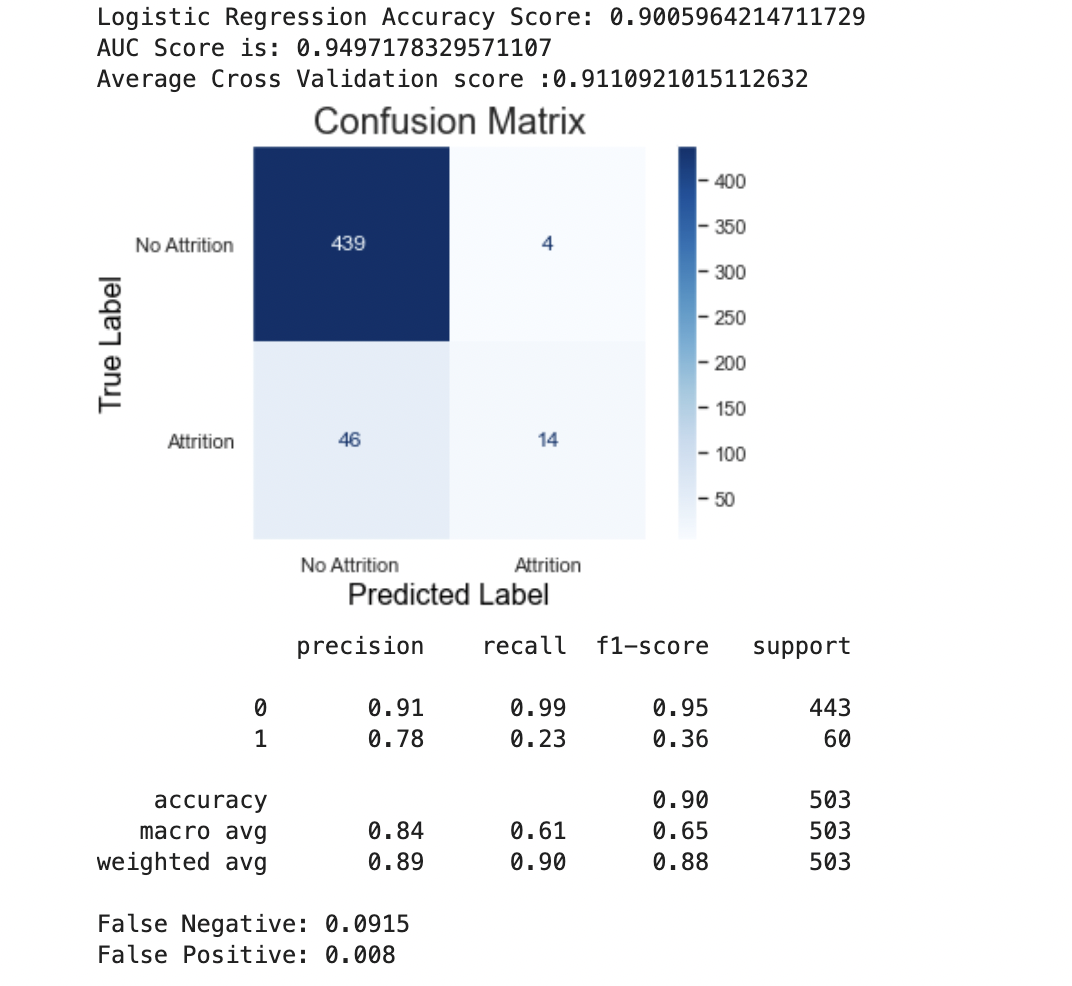
Logistic Regression
Using Logistic Regression, I performed four different models, using a combination of scaled/non-scaled data, and with and withou RFE Results are shown below:
| Model | Accuracy | AUC | False Negative |
|---|---|---|---|
| Logistic Regression - Scaled Data | 0.934 | 0.972 | 0.052 |
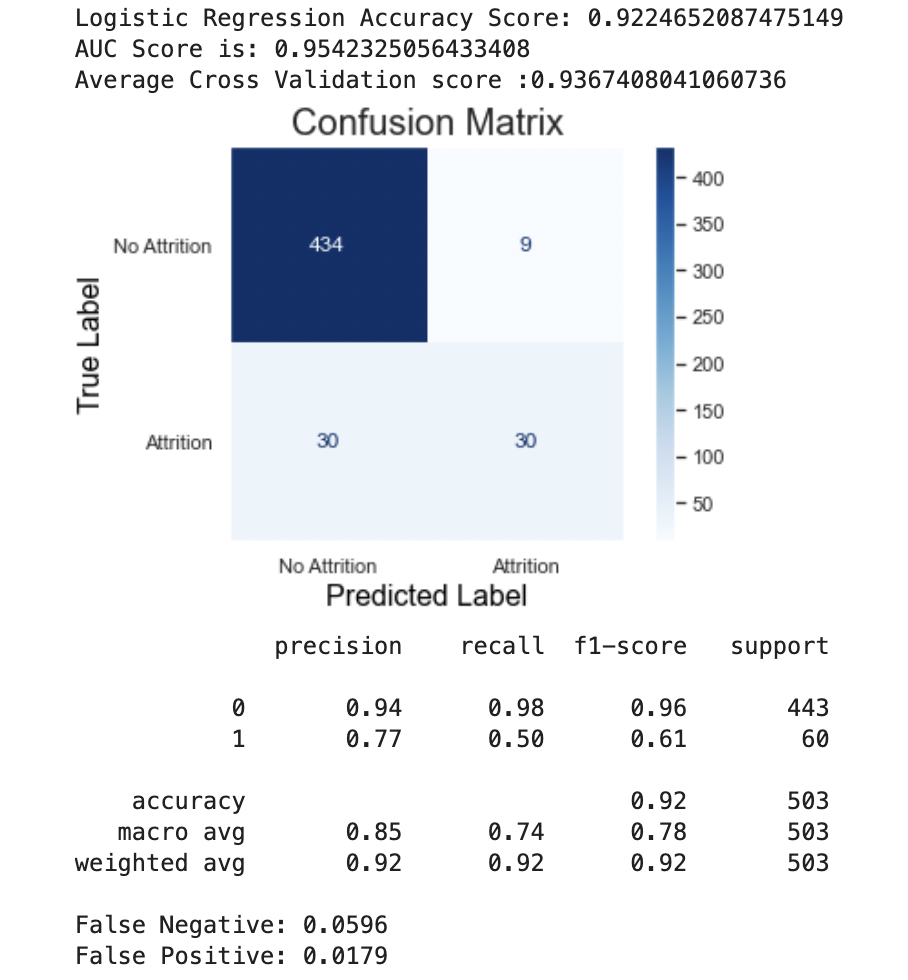
| Logistic Regression - Non-Scaled Data | 0.922 | 0.945 | 0.060 |
| Logistic Regression - Scaled w/RFE Data | 0.903 | 0.909 | 0.076 |
| Logistic Regression - Non-Scaled w/RFE Data | 0.928 | 0.967 | 0.050 |
It seems like Logistic Regression is overfitting. We will compare this later on with the other models.
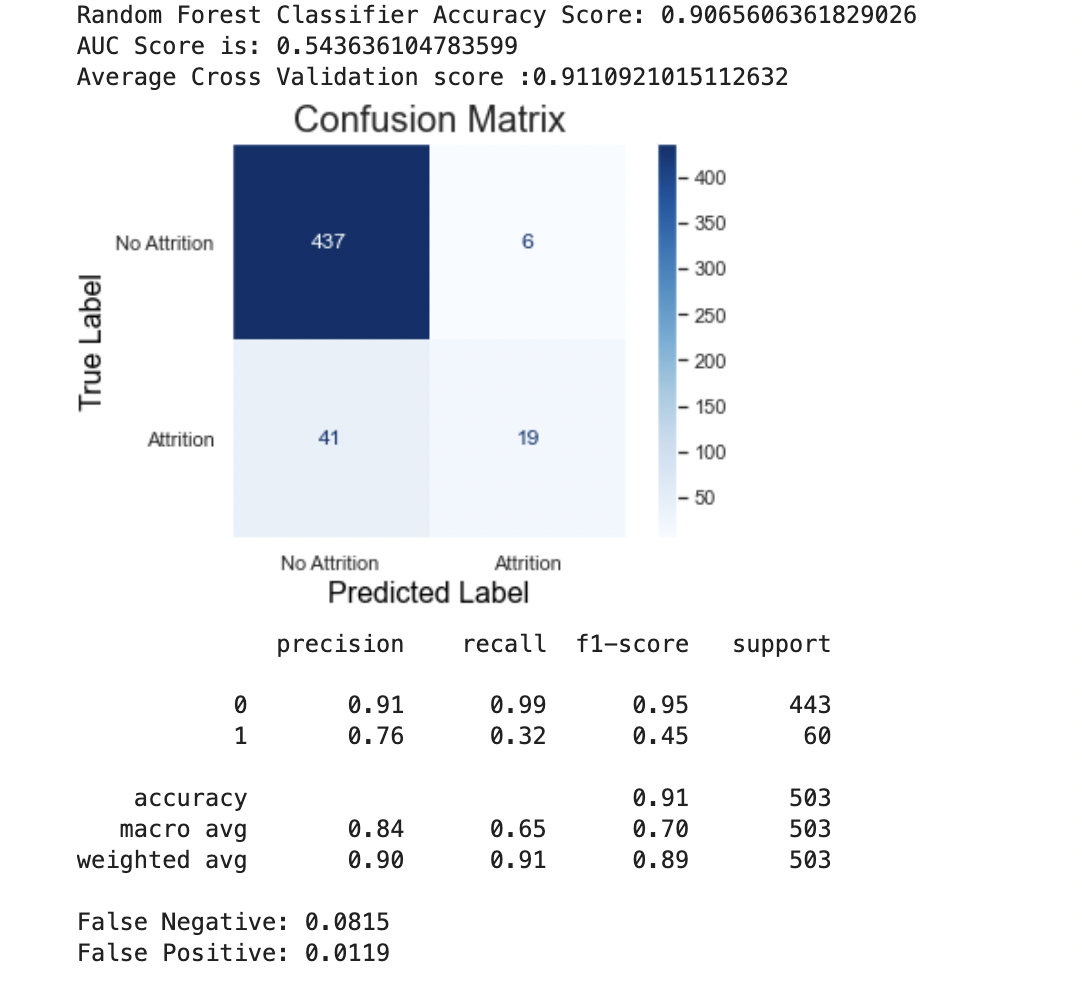
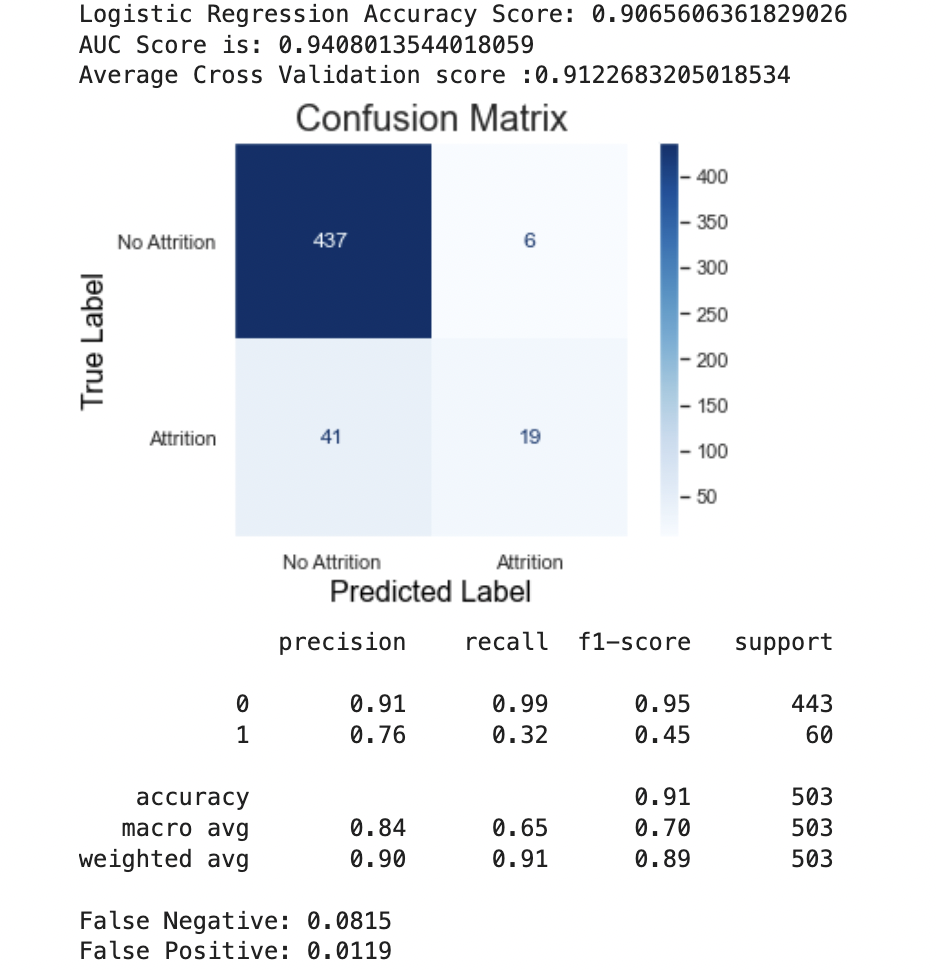
Random Forest
I decided to see how RFE worked with Random Forest,and the results were negligible for the most part. The false negative was lower with the RFE, but still was higher than Logistic Regression. Because Random Forest introduces bagging and random sampling of features, it leads me to believe that Logistic Regression indeed has an overfiting problem
| Model | Accuracy | AUC | False Negative |
|---|---|---|---|
| Random Forest - wo/RFE | 0.901 | 0.950 | 0.092 |
| Random Forest - w/RFE | 0.907 | 0.950 | 0.082 |
The Confusion Matrix:
For Non-RFE:
For RFE:
Extra Trees
The Extra Trees and Random Forest w/RFE yielded similar results
| Model | Accuracy | AUC | False Negative |
|---|---|---|---|
| Extra Trees | 0.907 | 0.941 | 0.082 |
The Confusion Matrix:
Gradient Boosting
Gradient Boosting does perform better than Random Forest and Extra Trees, but also known to overfit.
| Model | Accuracy | AUC | False Negative |
|---|---|---|---|
| Gradient Boosting | 0.922 | 0.954 | 0.060 |
The Confusion Matrix:
Conclusion
While Logistic Regression did perform better in terms of accuracy and lower false negatives, I believe it is due to overfitting. As far as Random Forest, Extra Trees, and Gradient Boosting, the latter performed the best in terms of accuracy and lower false negatives.
Enhancements are needed, especially in terms of reducing overfitting due to low number of observations. Also, need to investigate more into how I can improve the recall which is very low for the non-Logistic Regression models.
In terms of what I wanted to accomplish, I did learn about various methods like Recursive Feature Elimination and efficient way to use column transformers. I did look at various sites for help, and is linked in the jupyter notebook.